
At Zia Consulting, we would like to run Alfresco Content Services (ACS) on a Kubernetes (k8s) cluster. To do this, we need to understand the current state of Kubernetes and the necessary tools to manage Alfresco. Since many of our clients are in different states of Kubernetes adoption, it falls on us to give the appropriate recommendations. This is going to be a series of articles that starts with an article on Kubernetes. Stay tuned for future articles that will show how to set up ACS on a Kubernetes Cluster for development and production.
There are several deployment methods to install Alfresco. Apart from the supported war-based deployments, Alfresco is moving towards a containerized deployment pattern. Alfresco supports Kubernetes based container deployments for production. There are also other recommended containerized deployment methods for non-production use. In this article series, we will look at using both dev and production-based deployment methods.

Vijay Prince
Zia Consulting,
Solution Architect
In this article, we will discuss the following three items:
- What is Kubernetes
- Why use Kubernetes
- How to use Kubernetes
The core problem solved by Kubernetes is desired state management of clustered software deployments. For example, we can configure what images to use, the number of instances to run, network, disk resources and other aspects that are needed to maintain the application in the desired state.
Kubernetes provides services like:
- Service Discovery
- Load Balancing
- Automated Rollout and Rollback
- Automatic Bin packing
- Automatic healing
- Secret and app config management
In short, Kubernetes allows us to declare how our application should be run. Using this definition, Kubernetes uses its services to maintain the desired state as defined. Kubernetes allows system administrators to manage both on-prem and cloud resources efficiently.
Kubernetes Components
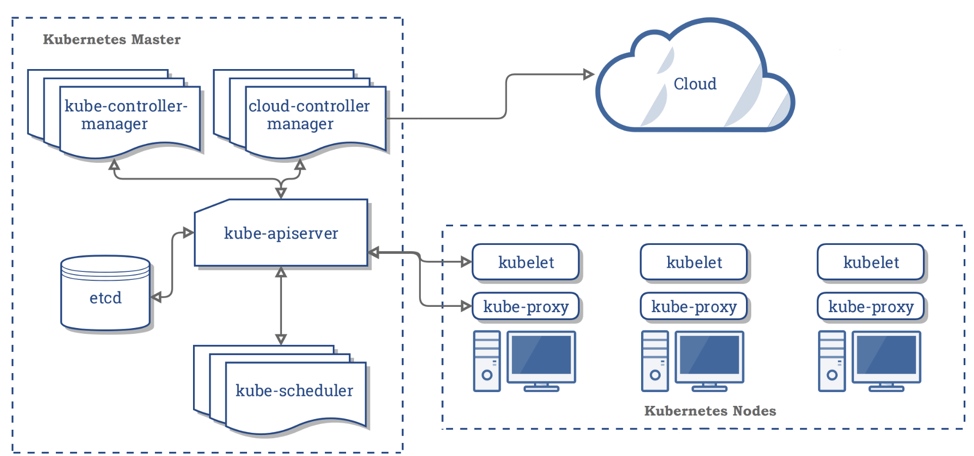
Source: Kubernetes
There are 2 main components.
- Kubernetes Master
- Kubernetes Node
The Kubernetes Master component is responsible for managing all of the Kubernetes resources in the nodes. Typically, there are multiple clustered masters. In development we may run with a single master. The Kubernetes master has the following components:
- kube-apiserver – exposes the k8s API and is the interface for the k8s master
- etcd – is a key value store that distributes data between cluster nodes
- kube-scheduler – assigns pods (more on this in a bit) to nodes
- kube-controller-manager – uses the replication controller, endpoints controller, namespace controller and serviceaccounts controller to maintain the desired state of the cluster
- cloud-controller-manager – beta component that was extract from k8s core, interacts with cloud provider when cluster components are delivered by a cloud provider
Kubernetes Nodes have the following components:
- kubelet – runs on every node and registers the node with the kube-apiserver
- kube-proxy – is a network proxy that runs on every node
- Container Runtime – runs containers in pods
Kubernetes Node

Source: Kubernetes
A Kubernetes Node contains pods. Pods are the smallest objects that Kubernetes controls. Kubernetes manages pods and it does not directly manage the contents of the pods. As shown in the figure above, a pod can use multiple containers and volumes.
A container is a packaging mechanism that allows an application and its dependencies to be packaged into a digitally sealed image that can be run consistently in multiple environments.
A Kubernetes volume is a named storage location that allows data to be shared between multiple containers inside a pod. The lifetime of a container and a volume inside a pod is determined by the lifetime of the pod.
K8s Desired State
In this section, I show how you define the desired state of a Kubernetes Cluster using YAML. More details on this format can be found here: https://yaml.org/spec/1.2/spec.html. Kubernetes allows us to use either YAML or JSON format. It is recommended to use YAML over JSON.
Using these YAML files to configure the desired state helps us track changes using source control and gives us the flexibility to add complex structures that are not possible from the command line. YAML is made up of key-value pairs (Maps) and Lists. Never use tabs when editing the YAML files.
This example shows the desired state for the example cluster I describe below.
—
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: k8s-client
labels:
release: test
app: client
spec:
replicas: 3
selector:
matchLabels:
release: test
app: client
template:
metadata:
labels:
release: test
app: client
spec:
containers:
- name: k8s-client-container
image: vprince/k8s-client-image:latest
ports:
- containerPort: 8080
---
kind: Service
apiVersion: v1
metadata:
name: k8s-client-service
spec:
type: NodePort
selector:
app: client
release: test
ports:
- nodePort: 30164
port: 8080
To deploy a Kubernetes application, there are 3 main pieces that are needed. They are:
- Pod – references containers and volumes
- ReplicaSet – describes how many pod instances should be maintained
- Service – is used to expose the application over the network to external requests
In the example above, you will notice we use 2 types of Kubernetes objects, a Deployment and a Service.
A Deployment provides the necessary details for Pods and ReplicaSets. When a Pod with a unique IP dies, Kubernetes creates a new Pod with a different IP. To allow uninterrupted service, we need a way to abstract this functionality. A Kubernetes Service is used to abstract the access to the pods.
In the example, we have a Service called k8s-client-service and Deployment called k8s-client. The deployment configuration specifies that we need 3 pods running with the container loaded from the vprince/k8s-client-image:latest image. These containers will expose the application on port 8080. This port is exposed internally in the cluster. The service configuration maps the internal port 8080 to an external port 30164. An external user will only be able to access the Kubernetes application using port 30164.
K8s Deployment – Rolling
The people using an application will want to have availability at all times. At the same time, the business would like to update the application functionality regularly. To allow for these use cases, Kubernetes allows us to release regular application updates without affecting the users. In this section, we talk about one type of deployment called Rolling Deployment.

One of the advantages of Kubernetes is the ease of managing an upgrade. In this diagram, I show how a rolling deployment is done.
- When we are ready to deploy a new version (V2), we make the necessary changes in the Deployment definition and tell Kubernetes to apply the changes. The deployment will now create a 4th replica of the application with version V2.
- When the container is up and it passes the liveness and readiness tests, it is added to the service. A liveness test shows if a container is unable to make progress due to deadlocks or other reasons. A readiness test shows if a container is ready to receive traffic. On slow starting containers, we can use startup probes. This disables the liveness and readiness test at startup. After startup, the liveness probe (mechanism to recreate a non-responsive container) starts monitoring the service.
- After a V2 container is up, one of the old V1 containers can be killed. This container is first removed from the service and then killed after waiting for the default or configured pod grace period. This allows existing processing to be completed.
The above three steps are repeated for all the other replicas till all of the replicas are running version V2 of the application.
The other most used deployment methods are:
- Blue/Green Deployment: In this deployment approach, a new set of containers with version V2 are spun up. When the health checks have passed, the load balancer is updated to point to V2 containers and the V1 containers are killed after the pod grace period.
- Canary Deployment: In this deployment approach, a small number of V2 containers are released to be used by a subset of users in production. This reduces risk by allowing only a small number of users to be affected if any major issue is found that would result in a rollback.
Kubernetes is changing the way we build, deploy and manage our applications. Alfresco has started using Kubernetes to deploy their software. In my next article, I will be showing how to run Alfresco Content Services on a developers laptop using Docker for Desktop.