
Capture opportunities have challenged Zia in the past. They require configuration on documents that are highly variable, like you would see in accounts payable, logistics, health, insurance, and other verticals. These opportunities typically need more hours of configuration to create an accurate solution.
The Future State Systems (FSS) Accelerator greatly speeds development time on projects involving documents with at least a little bit of structure. This involves invoices and other documents where data is often labelled well or found in a consistent location on a page, but the structure and keywords can vary by vendor. FSS Accelerator allows you to create templates for each variation of a document with little time or effort involved. Additionally, it can help with document merging so that no additional classification work is needed.

How It Works
After you’ve installed the FSS Accelerator, you will be able to log in at http(s)://[transact URL]:[port]/accelerator-api and configure it. The configuration involves creating templates for each variation of a document. This will result in very high confidence classification and extraction results. Additionally, the entire template creation and testing process occurs on a single web page. This saves a lot of time and clicks compared to Ephesoft Transact.
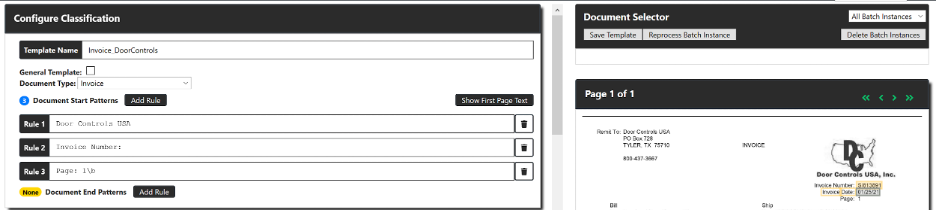
Configuring classification
To start, you’ll identify pattern(s) for the first page of each variation. More than one pattern can be used and are especially encouraged in situations where a single vendor has multiple document variants (of the same document type or different document types). FSS Accelerator prioritizes templates with more start patterns. As more patterns are specified, the more specific a template should be. A document end pattern can be specified but isn’t required. The end pattern is best used on variations where all pages look very similar, like when the header information is repeated on every page.
For most templates, three start patterns should be set up: the vendor (name, address, phone number, etc.), the document type, and the first page. If a good identifier of a first page isn’t available, then an end pattern should be set up instead.
Extracting data
Once you have configured classification, you can then add rules for extracting data. Two methods of data extraction are available: key-value and regex extraction, and the ability to hardcode values. They key-value extraction works similarly to Ephesoft’s key-value, but since the rules only apply to a single variation of a document, placing zones and deciding key and value regular expressions don’t require as much care. When you place the boxes, the value defaults to a .+ regular expression (meaning it will extract any string(s) completely encased inside the zone) and there’s a button to populate the key with the words inside its zone. For most cases, it’s fine to populate the key and move to the next field. However, sometimes it’s wise to make slight modifications to the key regular expression. This would include escaping characters that have different meanings in regex or making some spaces optional.

The other form of extraction allows you to specify a regex pattern. The first time it matches any text on the document, it will extract the value. This method should be reserved for values that have a distinct pattern like social security numbers or PO numbers if the company uses a unique pattern. For other cases, key-value should be more accurate and just as fast to define.
Besides index fields, FSS Accelerator also supports table extraction. The interface works almost exactly like Ephesoft’s table extraction with the column coordinates and regex boxes checked. This is usually the most accurate way to extract table data as long as the documents are consistently scanned or aren’t passing through a scanner. Having these table templates coupled with the index field rules makes for a well-organized project that’s easy to troubleshoot and update.
Handy Features
FSS Accelerator can work on variations that don’t have an official template and make template generation faster. You can create a “General Templates” that will be used on pages that don’t match any existing templates. These general templates contain generic wording like invoice to allow you to classify the pages. Then, you can attempt to build a complete document, for instance, by using page numbers.
FSS Accelerator will then take documents that just match a general template and run them against all extraction rules that are set to be reusable. All extraction rules are set to reusable by default, but any extraction rules that are highly-specific to a single template can be set to not allow reuse. This allows for documents that haven’t been configured as templates to classify and still have a decent shot at having data extracted.
A separate admin interface not only configures batch class settings and templates. It also tests batches without needing to go back and forth between FSS Accelerator and Transact. Once any changes have been made, a batch can be re-processed in mere milliseconds (compared to up to minutes on the Transact side). The admin interface includes configuration management. Templates can be exported and imported so you can develop these in a lower environment and deploy to production and other environments. These exports are an XML file, allowing for storage and change tracking in source control.

Configuration Options
There are many configuration options in FSS Accelerator that allow you to fine-tune the behavior of the application:
- Send all batches through FSS Accelerator, or just Unknown documents.
- What happens when a value isn’t extracted for a field
a. Leave blank or display the highest-ranked option from the other templates
b. Only display an option that matches the validation rules for that field
How to separate documents
a. Each file is a single document
b. Document start/end patterns
c. Hybrid – A new file starts a new document, but each file can contain multiple documents