
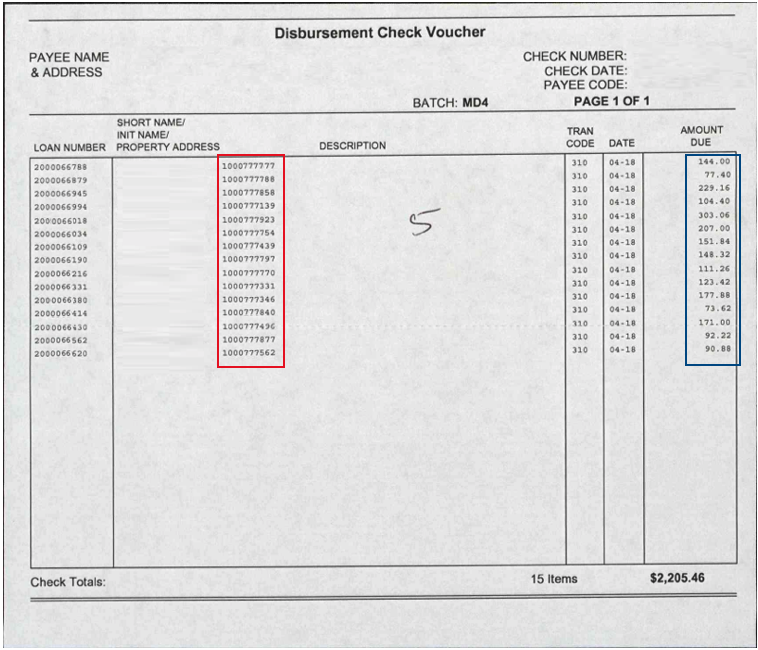
When you need to extract tabular data from documents, Ephesoft makes it fairly simple through its existing Table Extraction functionality. This works great when the table is well-defined—a standard format with clear text and column headers can provide reliable results. But what about when your table’s format is less predictable?

For example, we were working with loan documents and needed to extract 10-digit certificate numbers and an associated dollar amount. The problem is that we’re not processing these payment documents from a single customer. They can be generated by the customer themselves, and while some customers do reuse formats, we were provided about 15 different formats for the proof of concept work. We could configure more and more table extraction rules, but it doesn’t scale well. In looking at the examples below, you’ll see that some documents have no column headers or other information that we can key off of.

The Solution: Line-by-Line Analysis
Although these documents aren’t a perfect fit for Ephesoft’s Table Extraction, we can create a custom solution to extract the values. Our solution analyzes each line of text on the page, searches for lines where both values are present, and extracts the pair. There are a couple of key points that make this possible. First, each certificate number and dollar amount pair are on the same line. This is true across all samples we’ve seen. Second, we have very predictable data formats which are unlikely to appear coincidentally.

The challenge with this approach is that Ephesoft doesn’t give us lines of text. Instead, the optical character recognition (OCR) results contain the individual words on the page and their coordinates. This means that we have to construct the lines ourselves.
Below is a rough representation of how words appear in the OCR results. For each word on the page, we get the coordinates of the word as a bounding box (represented as green boxes). For each bounding box, we get the X-Y coordinates relative to the upper-left corner of the page (represented as red lines).

Our algorithm inspects each word’s bounding box, and calculates its vertical midpoint. The algorithm builds lines by checking each word’s vertical midpoint to see if it’s within the vertical bounds of the other words on the line. If the current word’s midpoint is within the bounds, it is considered part of the line of text, and the line’s bounds are extended. If the current word’s midpoint is not within the line’s bound, then the word is considered the start of a new line.
In the animation below, we can see how a line is built up from the individual words. The purple line through each word represents its midpoint, and the algorithm checks that the midpoint is within the bounds of the line (represented in orange). After all words are inspected, the words are grouped together into a logical line of text.

Great! Now we have the ability to identify lines of text across the page. Unfortunately, real-world documents aren’t this nice. It’s quite common for documents (especially scanned pages) to be slightly skewed. Using the same algorithm which inspects midpoints, we can still find groups of text that appear to belong together. In the example below, the same text is skewed by 10°. As we run the algorithm, we now see two groups of text: red on the left, and blue on the right. We’re no longer able to recognize that these two groups actually belong to the same line of text.
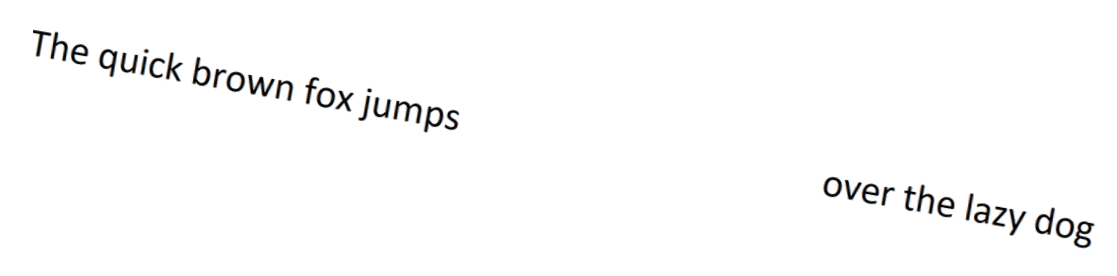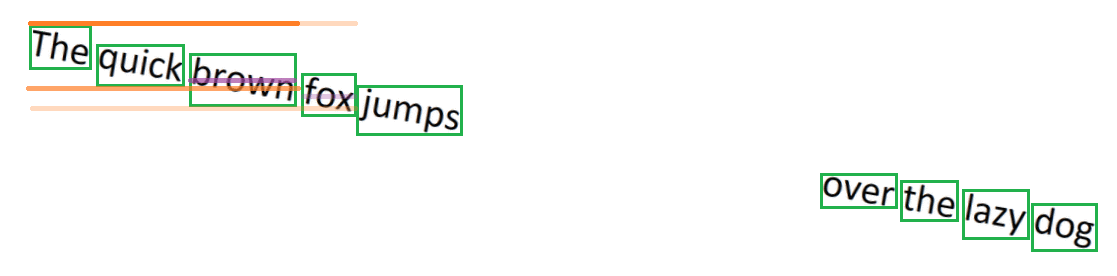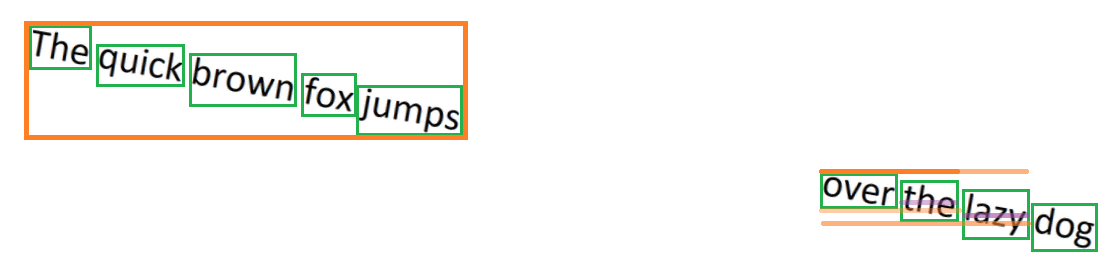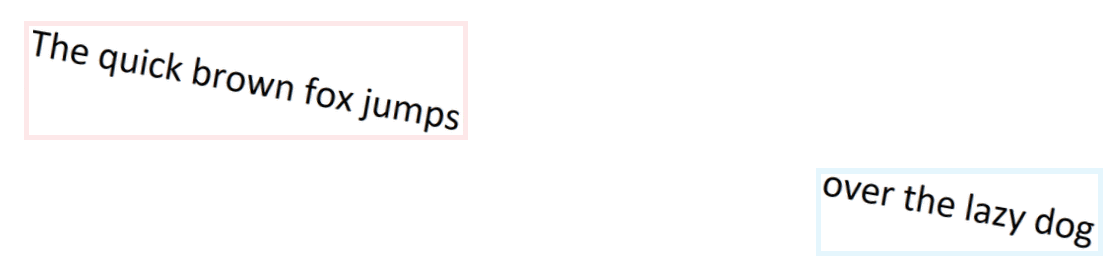
This is a big problem. Consider if the certificate number were in the red group, and the dollar amount were in the blue group. These values would be considered to be on separate lines, and we wouldn’t extract the line item.
To correct this problem, we must deskew the page. This first requires that we calculate how much the page is already skewed, so that we can “undo” the effect. The skew is calculated by finding the skew angle for each group of text and computing an average for each group on the page. Once we have the page’s average skew, we use trigonometry to rotate the words back into alignment.

This deskew transformation returns the words to their proper, unskewed positions. We now repeat our algorithm to properly identify text as a single line.
With all of our text properly aligned, we inspect the words on each line to see if they match the expected format either a certificate number or a dollar amount. When both of these values are found within a line, the line item is extracted into the table.
Results: Does it work?
In our first test set there were around 150 pages and around 500 total payments. This set resulted in 100% extraction. We then conducted an expanded test set of around 500 pages where we achieved around 95% extraction. The only errors were caused by OCR results (not deskewing/detection logic). We also found several cases where the text on page was incorrect (e.g., certificate number missing a digit, dollar amount missing a digit $100.5).
If you’d like more information on line-based text extraction and how it can be implemented, please contact us today.