
As a refresher, FSS Accelerator increases the ability to automate highly variant documents like accounts payable, invoices, POs, logistics documentation, and medical forms. It also speeds up extraction configuration, as the extraction UI used for field and table rules is well optimized onto a single screen. In addition, extraction rules are easily reusable.
New Features
The most important feature from a document processing perspective is a new “fuzzy” feature to complement the existing regex and key-value features for identifying key text. The fuzzy feature, not to be confused with the Fuzzy DB feature in Transact, allows a text string to be specified along with the fuzziness level. This sets how many characters can be incorrect. If the string to be identified is “Consolidated Amalgamated” with a fuzzy level of 90%, then 10% of the characters (i.e., 2.4 round to 2) can be incorrect. If the optical character recognition (OCR) results have “Consolidafed 4malgamated” (i.e., 2 bad characters) it would still be a match. The string comparison is case insensitive. This is useful when processing scanned or faxed documents that often have poor OCR quality. Note that the fuzzy feature is available for both classification rules and the key in a key-value extraction rule.
Another helpful feature is that the document configuration screen shows the OCR results pane, with the results of all pages in a document. As you can see by the screenshot above, this is broken out by page. This makes it more straightforward to look at the OCR text and pick the correct rules to use.
In addition, Accelerator now allows field-level validation and transformation rules. Why do we need validation rules when Transact already has these? These are template-level validation rules, rather than document-level rules. This means that you are now able to fine tune the validation rules to allow for the subtle format changes across multiple document formats. This is very helpful with invoices, since invoice numbers and dates can have a large variety of formats. Like the validation rules, transformation rules can also be created for each template. It may be that you have some dates in the standard international format of day/month/year, which is difficult to decipher from US month/day/year. Now you can create a transformation to normalize a date for a particular template.
Lessons Learned
Accelerator works really well with “clean” samples (i.e., converted vector PDFs or PDFs with a text layer). In these cases, the OCR data is close to perfect. More specifically, it is perfect if there is a text layer and no OCR is required. Thus, both classification and extraction work well. We have encountered some issues with poor quality samples, or samples that are scans or scans of scans. In these cases, the text is not crisp. Speckles, or other scanning artifacts, are introduced. It is harder for the OCR engine to get accurate text results, making it harder to identify the templates or extraction keys. Note that this issue is not specific to Accelerator, but also happens with Transact classification and extraction. With OCR, it’s garbage in and garbage out; low quality images lead to low quality OCR results. If you find yourself spending a lot of time tweaking templates to account for OCR problems, then stop, take a deep breath and go talk to the end users again. You will always get better results when working with original documents, such as PDF invoices. However, using original documents may require end users to change their processes if they are currently used to dealing with printed and scanned documents. Sometimes, technology problems can boil down to process issues that require changes to document processing workflow at a human level.
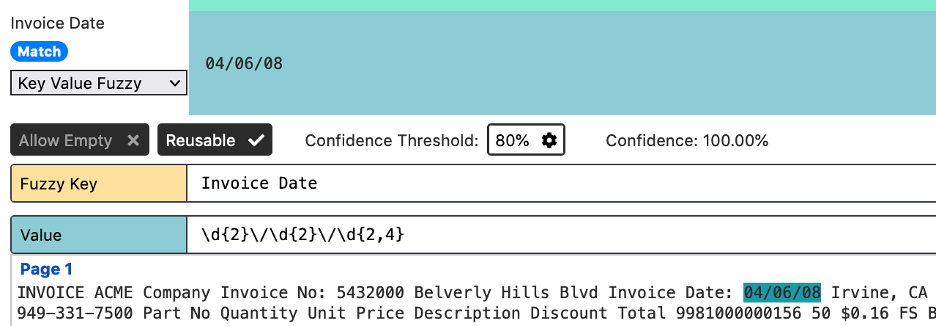
Accelerator KV extraction rules default to a regex value of .+ which means the rule will extract any text within the value rectangle. When creating templates, you should always create more specific rules for invoice numbers, date, names, etc. Using more specific rules allows for better rule reuse when creating new template extraction rules. The .+ rules extract anything. Therefore, these rules are not helpful for reuse because they will extract any text value.
In conclusion, the recent changes to FSS Accelerator have improvements in both the amount of time needed to set up templates, as well as the classification and extraction results. Users should upgrade as soon as possible to realize these benefits. Contact us today for a personalized demo.

ABOUT THE AUTHOR
Ian Sprod, Enterprise Architect at Zia Consulting
Ian has been with Zia for 10 years focussing on document capture and content management projects. He has previously worked on numerous web and enterprise software development projects in both management and developer roles. For fun he likes to hang out with his kids, as well as hike and bike in the Rocky Mountains of Colorado.